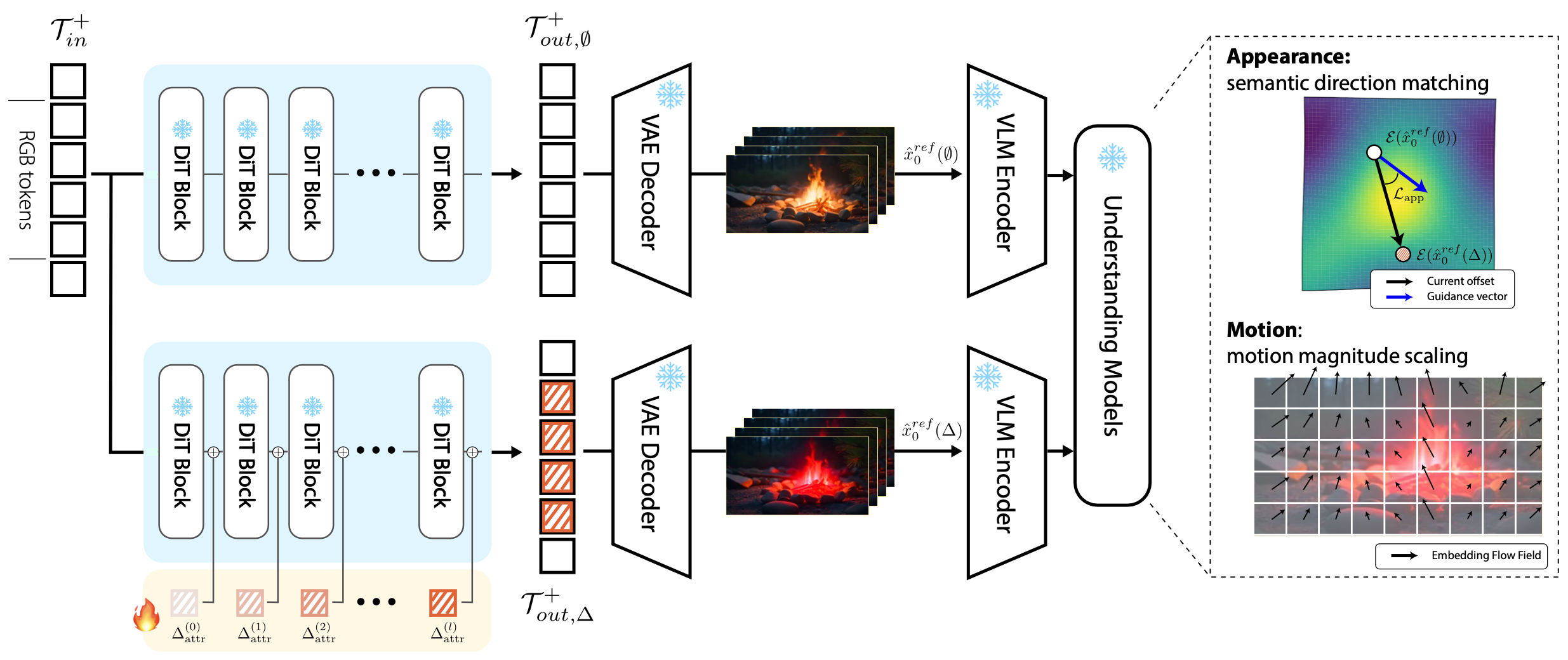
Our TokenDial Framework
Given a pretrained text-to-video generation model, TokenDial learns lightweight slider controls for continuous video editing without modifying the backbone model weights.
Each slider corresponds to a semantic attribute, such as appearance or motion, and allows users to smoothly adjust the strength of an edit from weaker to stronger effects.
Instead of changing the model through full fine-tuning, TokenDial operates in the intermediate video token space.
Our method learns additive token offsets that are injected into spatiotemporal visual patch tokens inside the video diffusion transformer.
For appearance sliders, we use semantic direction matching in visual embedding space to encourage the edited output toward the desired attribute direction. For motion sliders, we use motion magnitude scaling to supervise controlled changes in temporal dynamics.
These learned offsets act as reusable control directions, enabling predictable and progressive changes while largely preserving the identity, background, and overall scene layout of the original generation.
For appearance sliders, we use semantic direction matching in visual embedding space to encourage the edited output toward the desired attribute direction. For motion sliders, we use motion magnitude scaling to supervise controlled changes in temporal dynamics.
These learned offsets act as reusable control directions, enabling predictable and progressive changes while largely preserving the identity, background, and overall scene layout of the original generation.